
Self-Service ML Models for Chemical Data: Ready to Use, Zero Setup Required
Training a custom machine learning model for chemical formulation or property prediction used to be a long process. For most R&D labs, it meant weeks spent setting up software environments, wrestling with data engineering frameworks, writing custom validation loops, and scaling a steep internal coding curve. By the time a functional predictive model was ready, valuable experimentation windows had often passed.
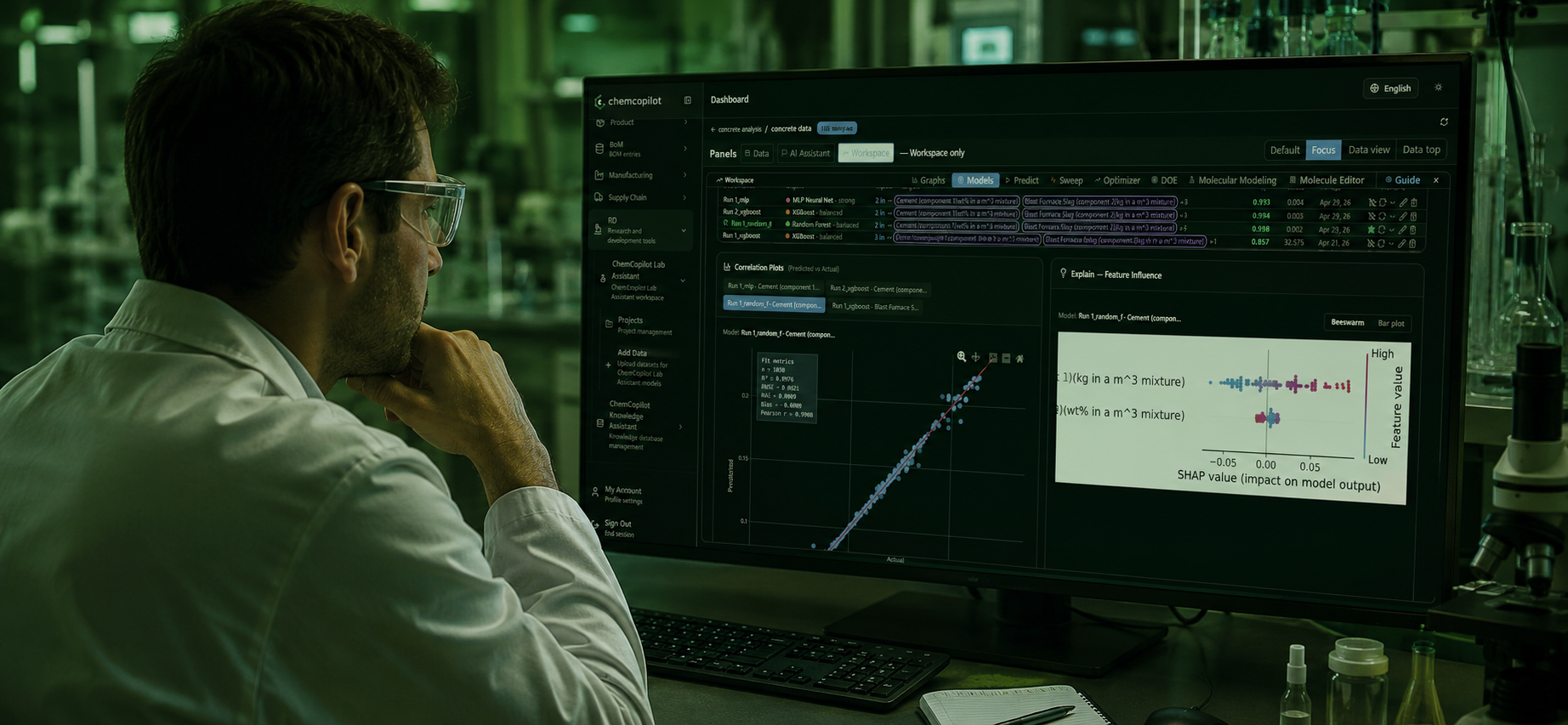
The model library inside the **ChemCopilot Agent Lab** changes this paradigm completely. Formulators can now upload tabular chemistry datasets, choose a targeted machine learning algorithm directly from the control panel, and generate highly accurate property predictions in minutes—all without touching a single line of code.
Custom ML Pipelines
Weeks of Technical FrictionRequires manual dataset formatting, script debugging, custom training loops, and environment setup before generating a baseline prediction model.
Preset Model Library
Instant Tabular ExecutionUpload a standard tabular CSV file, choose an algorithm from the workspace panel, select an automated preset, and view optimization metrics instantly.
Six Models, One Panel: Complete Material Strategies
Different chemical problems require different mathematical optimization pathways. The preset library provides access to six distinct machine learning strategies, allowing you to find patterns in your raw laboratory data effectively:
XGBoost
Fast
Bal
Str
The best all-rounder for tabular chemistry datasets. It handles missing values, experimental anomalies, and mixed feature types out of the box with strong accuracy.
Random Forest
Fast
Bal
Str
Highly robust to experimental outliers and deeply transparent. It provides excellent feature importance metrics when you need to explain your results to stakeholders.
MLP Neural Net
Fast
Bal
Str
Excellent at capturing complex, non-linear chemical patterns. Use this when your formulation data contains multiple interacting ingredients or hidden synergistic effects.
TabPFN
A zero-tuning foundation model built specifically for small tabular datasets. It delivers high predictive accuracy with zero configuration or hyperparameter tuning required.
K-Nearest Neighbors (KNN)
Predicts target formulation behaviors based on the closest historical observations in your data lake. Simple, perfectly transparent, and highly effective for matching past runs.
Extra Trees
Offers much faster model training phases than a traditional Random Forest while preserving comparable accuracy metrics. A highly efficient baseline choice.
Adjusting the Speed-versus-Accuracy Dial
The core algorithms—**XGBoost, Random Forest, and MLP**—ship with three distinct training presets. Think of these presets as a simple speed-versus-accuracy dial that you can turn without adjusting complex code hyper-parameters:
- Fast Preset: Ideal for screening or exploring your data quickly. It trades a small margin of precision for processing speed, making it well-suited for early-stage brainstorming iterations.
- Balanced Preset (Default): Carefully tuned to balance runtimes and accuracy. It delivers reliable results across most structural chemical properties out of the box.
- Strong Preset: Maximum accuracy mode. It expands the algorithmic search pattern and runs hyperparameter optimization loops over a broader grid. Turn this on when your final lab targets require tight tolerances.
Step-by-Step Workflow: Getting Started with Your Lab Data
Running a prediction iteration within ChemCopilot follows a clean, highly structured, four-stage process:
Upload Dataset
Drop in a standard tabular CSV file. Your proprietary data remains completely private and is never used to train shared models.
Select Model
Pick an architecture from the control panel. If you are unsure where to begin, choose XGBoost on Balanced.
Choose Preset
Run a quick Fast preset for a baseline check, then shift the selector to Strong once you are ready for maximum precision.
Review Outputs
Analyze generated validation metrics, view feature importance weights, and instantly export predictions to guide your bench team.
Quick Reference Selection Guide
Use this matrix to quickly select the ideal model architecture based on your current data constraints and target objectives:
| Your Laboratory Scenario | Recommended Architecture Choice | Default Preset Focus |
|---|---|---|
| New to machine learning modeling | XGBoost | Balanced |
| Need explicit results explainability for stakeholders | Random Forest | Balanced |
| Highly complex, non-linear variable interaction | MLP Neural Net | Strong |
| Small dataset context (under 200 data rows) | TabPFN | Zero Tuning Native |
| Need a very fast, lightweight performance baseline | Extra Trees | Zero Tuning Native |
Because there are no execution or hardware usage limits per project, you can run your data against multiple model configurations simultaneously and compare their predictive accuracy side-by-side to find the optimal framework for your material goals.