
The Hidden Cost of Repeated Experiments: Quantifying R&D Waste in Chemical Laboratories Worldwide

Why the most expensive failure in industrial science is not the experiment that went wrong — but the one that was never recorded.
Every synthetic chemist recognises the sensation: standing at the bench, preparing a reactor run that feels somehow familiar — a nagging suspicion that some version of this experiment was conducted two floors up, three years ago, by a colleague who has long since departed. The notebook from that work — if it survives at all — is buried in a filing cabinet, transcribed in handwriting that only its author could reliably decode. So the experiment is run again, from scratch, consuming reagents, instrument time, analyst hours, and crucially, weeks of calendar time that a product-development schedule cannot afford to lose.
This scenario is not an anecdote. It is a global systemic condition. Across chemical manufacturing, specialty materials, agrochemicals, and pharmaceutical process development, a substantial fraction of every R&D budget is consumed not in advancing the frontier of knowledge, but in rebuilding ground already occupied. The cost is enormous, measurable, and — this is the uncomfortable truth — largely preventable.
The Economic Anatomy of R&D Waste: What the Numbers Actually Say
To understand the scale of what is being squandered, it is necessary to begin not with estimation but with primary data. The landmark analysis published in PLOS Biology by Freedman, Cockburn, and Simcoe (2015) remains the most rigorous attempt to quantify irreproducibility costs in preclinical science. Their conclusion — that roughly 50% of preclinical research in the United States alone cannot be reproduced, generating a direct economic loss of approximately US$28 billion annually — shocked the scientific establishment at the time of publication. A decade on, it reads less as a provocation and more as a conservative undercount.
Extrapolating from that baseline using IQVIA data that places the United States at roughly 45% of global early-stage R&D activity, Bio-Rad’s 2022 analysis estimated that the globally irreproducible research figure approaches US$90 billion per year. This is not money spent on discovering that a hypothesis was incorrect — that is the ordinary, productive cost of scientific inquiry. This is money consumed by experiments whose outcomes cannot be trusted, replicated, or built upon, because the underlying data capture, laboratory protocols, or reporting structures were insufficient to make them reliable.

The chemical industry specifically contributed approximately €27 billion to global R&D expenditure in 2022, according to European Commission data. When the irreproducibility coefficient is applied to this figure, it implies that somewhere between €10 billion and €15 billion of that investment is effectively burned through structural inefficiency — not scientific ambition, not calculated risk, but waste arising from poor data management, absent traceability, and the compulsive tendency to rerun what has not been recorded.
Four Mechanisms That Drive Experimental Repetition in Chemical R&D
It would be intellectually lazy to attribute this waste to a single cause. The problem is architecturally complex, rooted in organisational behaviour, tooling constraints, and the cultural archaeology of how chemistry has historically been practised. Four primary mechanisms account for the overwhelming majority of unnecessary repetition.
1. Dark Data Accumulation: The Experiment That Cannot Be Found
CAS, the scientific information division of the American Chemical Society, defines dark data in R&D as experimental results, process observations, and analytical measurements that have been collected and stored but remain inaccessible to the researchers who need them. Estimates from Splunk and IBM suggest that between 80% and 90% of data generated in industrial settings is dark: saved somewhere, findable by no one. A survey of global business and IT leaders cited by CAS found that 55% of all stored organisational data is dark, while 90% of respondents agreed that extracting value from this unstructured accumulation is a strategic imperative their organisations have not yet addressed.
In a chemical research context, dark data manifests as handwritten reactor logs whose metadata was never digitised, PDF-formatted synthesis reports filed by departure year rather than by compound or process, spectral data stored locally on an instrument computer since replaced, and trial results captured in personal spreadsheets that retired with their author. The consequence is textbook: a researcher in 2026 spends four weeks investigating the thermal stability profile of a polymer intermediate, unaware that an identical characterisation was conducted in 2019, abandoned due to a scope change, and never entered into any retrievable system. Four weeks of scientist time, materials, instrument booking, and analytical overhead: vaporised.

2. Knowledge Loss Through Attrition: The Departing Chemist Problem
Tacit knowledge — the operational intuition accumulated by an experienced formulation chemist who has coaxed a particular reactor through 200 batch runs — does not transfer automatically to a successor. It transfers through documentation, institutional memory systems, and deliberate capture processes. In the majority of chemical organisations operating today, none of these mechanisms function reliably. A senior researcher exits carrying the nuanced understanding of why a particular solvent ratio stabilises a heterogeneous catalyst under specific humidity conditions, why a mixing speed adjustment at the 40-minute mark prevents byproduct formation, why a batch from Supplier B consistently underperforms relative to ostensibly identical material from Supplier A.
When that researcher leaves — through retirement, voluntary departure, or the restructuring that has characterised the global chemical industry since 2023 — their successors begin the rediscovery process from an emptier starting point than they realise. Studies of R&D mismanagement published by Labiotech.eu have identified this “dilution of responsibility” as one of the most consistent drivers of expensive experimental redundancy in both large pharma and mid-sized industrial chemical firms.
3. Experimental Design Without Systematic Prior-Art Review
A structural problem documented across chemical R&D environments is the absence of a mandated process for querying internal experimental history before initiating a new trial. In academic and early-stage industrial settings, researchers routinely design experiments without any systematic search of their organisation’s own data — not out of negligence, but because the data infrastructure does not permit a rapid, meaningful search. The consequence documented by Dotmatics in their analysis of chemicals and materials R&D challenges is stark: when 80% of scientific decision-making depends on connecting structural properties to existing test data, and that test data is fragmented across incompatible ELNs, personal machines, and departmental databases, researchers operate in a state of involuntary ignorance about what their own organisation already knows.
4. The Sunk-Cost Experiment: Running What Should Have Been Stopped
The inverse of the unnecessary repeat is the experiment that continues well past the point where any rational analysis of existing data would recommend termination. Labiotech’s analysis of mismanaged R&D projects describes this as the sunk-cost fallacy in its most resource-intensive form: because significant investment has already been committed, project managers continue to sanction experimental cycles that are not generating proportional scientific value. Without a quantitative system that continuously evaluates the marginal informational return of each additional run against the cost of execution, decision-making defaults to human psychology rather than process intelligence.
Beyond Direct Expenditure: The Compound Cost Structure of Experimental Waste
Direct materials and analyst time represent only the first-order cost of repeated experiments. The compound cost structure is considerably more punishing. Consider the knock-on effects operating simultaneously when a single redundant experimental campaign runs for eight weeks in a mid-sized specialty chemical organisation.
Instrument time is consumed at the exclusion of other projects. Regulatory timelines shift, because the market submission that depended on this characterisation data is delayed. Capital investment in raw materials and reagents accumulates without corresponding knowledge generation. And — critically — the organisation’s opportunity cost compounds silently: a competitor who did not have to repeat this experiment has used those eight weeks to advance their development programme, narrow their time-to-market advantage, or file a patent claim on the formulation space your organisation was rediscovering.
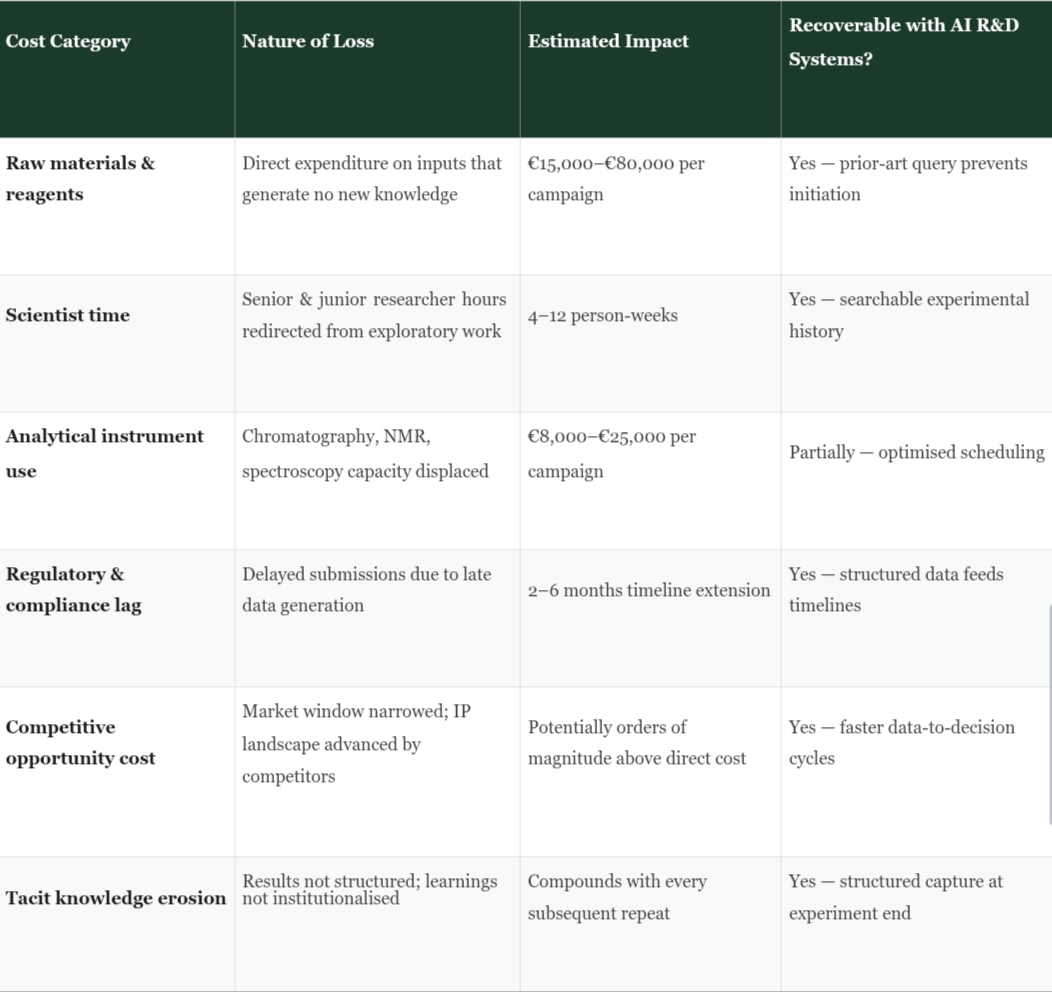
What makes this cost architecture so difficult to confront in management discussions is precisely its diffuseness. Unlike a failed batch that produces a tangible write-off, or a clinical trial discontinuation that generates a visible budget impact, the cost of the unnecessary repeat experiment is distributed invisibly across headcount, instrument schedules, and timeline slippage. It does not appear as a line item. It appears, instead, as a persistent, mystifying drag on R&D productivity that organisations attribute to the inherent difficulty of chemistry — when in reality, a significant fraction of it is an information infrastructure problem.
Structural Solutions: What It Actually Takes to Stop the Cycle
The research literature on R&D reproducibility — from Freedman’s cost analysis to the Lancet’s “Increasing Value, Reducing Waste” series (Macleod et al., 2014) — converges on a set of structural interventions that address the problem at its root. These are not philosophical reforms. They are engineering changes to the information systems through which experimental knowledge is captured, stored, connected, and activated.
The first imperative is centralised, structured knowledge capture at the point of experiment execution — not as an end-of-project documentation exercise, but as an intrinsic feature of the workflow itself. Every reaction parameter, every deviation from protocol, every anomalous observation and failed intermediate must be recorded in a format that is computationally searchable, contextually tagged, and permanently retrievable by any authorised member of the organisation regardless of when or where the original work was conducted.
The second is active prior-art querying as a mandatory precondition for experiment initiation. Before the first milligram of reagent is weighed, the informational question must be answered: has this, or something sufficiently similar, been examined before within this organisation’s own history? This requires not merely a keyword search but a chemical-intelligence query — one that understands structural similarity, functional equivalence, and process-condition overlap rather than simply matching text strings.
The third is predictive experiment prioritisation. Given a set of proposed experimental conditions, which combination is most likely to yield the highest informational return relative to what is already known? This is not a question that a spreadsheet, a laboratory notebook, or a legacy LIMS system can answer. It requires a machine learning architecture trained on the organisation’s own historical process data.
ChemCopilot: Building the Architecture That Stops Waste Before It Starts
This is precisely the problem that ChemCopilot was architected to solve — and it is worth being specific about how, because the solution space here is populated with partial answers that address individual symptoms while leaving the underlying pathology untreated.
ChemCopilot operates as an AI-native Product Lifecycle Management platform purpose-built for chemical R&D workflows. Its foundational design principle is that every experiment an organisation conducts should permanently enrich an intelligent, searchable, and continuously learning knowledge base — one that makes the cost of not consulting prior internal data higher than the cost of doing so. Experimental protocols, raw reaction parameters, intermediate observations, and final outcomes are captured in structured, machine-readable formats as a natural consequence of running the platform, not as a separate documentation burden imposed on scientists after the fact.
The platform’s AI agents do not merely store this data. They actively connect it: identifying structural relationships between compounds investigated years apart by different teams, flagging when a proposed experimental condition falls within the parameter space of a prior investigation, and surfacing the specific variable interactions — stirrer speed, solvent ratio, pH trajectory — that historical data identifies as predictive of outcome. Where a legacy LIMS presents a researcher with a search bar, ChemCopilot presents them with an intelligent interlocutor that already understands the chemistry of their organisation.
Critically, this intelligence is entirely private to each client. ChemCopilot’s federated isolation architecture — operating on dedicated Amazon Web Services infrastructure — ensures that an organisation’s proprietary formulations, process optimisation learnings, and experimental failures remain entirely within their own secure environment. The AI learns from your data and improves continuously; it does not share what it learns with any other client or contribute it to a generalised model. For organisations whose competitive advantage is precisely the accumulated tacit knowledge of decades of process chemistry, the security of that knowledge is non-negotiable.
The Productive Frontier Awaits: But Only After the Waste is Stopped
The global chemical industry is investing at scale in artificial intelligence, digital transformation, and sustainable innovation. It is simultaneously losing, by conservative estimate, tens of billions of dollars annually to a problem that is not fundamentally about the difficulty of chemistry — it is about the difficulty of remembering what chemistry has already been done.
The Lancet’s waste-reduction framework is unambiguous: the single most impactful lever available to research organisations seeking to improve the value generated per unit of R&D investment is improving the relevance of what gets studied. Relevance, in this context, means not repeating what is already known. It means building the information architecture that makes the full history of an organisation’s experimental work instantaneously available, intelligently contextualised, and actively integrated into the decision about what to do next.
The productive frontier — the genuinely novel compounds, the untested process conditions, the unexplored formulation space where competitive advantage is created — is not distant. It is simply obscured by the accumulated shadow of all the experiments that should not need to be run again. Clearing that shadow is not an aspiration. With the right platform architecture, it is an engineering problem that has been solved.
REFERENCES
Freedman LP, Cockburn IM, Simcoe TS. The Economics of Reproducibility in Preclinical Research. PLOS Biology 13(6): e1002165 (2015). doi:10.1371/journal.pbio.1002165
Bio-Rad. Are Costly Experimental Failures Causing a Reproducibility Crisis? (2022). Citing IQVIA Institute data, 2021.
European Commission / Statista. Total global R&D spending on chemicals by region, 2022. Published December 2023.
Macleod MR et al. Biomedical research: increasing value, reducing waste. Lancet 383: 101–104 (2014). doi:10.1016/S0140-6736(13)62329-6
CAS. Dark Data in R&D: How Knowledge Management Can Uncover Hidden Value. cas.org (2022).
Cogent Information Solutions. Dark Data: Unlocking the ~90% You Don’t Use (2025). Citing Splunk and IBM estimates.
Dotmatics. Faster, Please: Key Challenges in Chemicals and Materials R&D. dotmatics.com/blog (2023).
Labiotech.eu. The Hidden Costs of Mismanaged R&D Projects in Biotech and Pharma (2022).
Oliver Wyman. Chemical Industry Outlook for 2025 and Beyond. oliverwyman.com (January 2025).