
How AI Is Turning Molecular Fingerprints into Real-Time Formulation Decisions

The Problem With Sampling: Why Post-Hoc Analysis Is No Longer Sufficient
For most of chemistry's modern history, the act of understanding what is happening inside a reaction vessel has required patience — waiting for a sample to be withdrawn, carried to an instrument, processed, and finally interpreted. Today, that latency is collapsing. A new generation of AI-powered spectroscopic platforms can interrogate a molecular mixture continuously, interpret its vibrational signature in near-real-time, and feed actionable intelligence directly into formulation workflows — all before a single drop of product has left the reactor.
Every chemist has felt the friction: a reaction that looked promising by the end of the hour, but whose mechanistic story — the transient intermediates, the momentary pH excursion, the crystallization onset that occurred forty minutes in — was already irretrievable by the time the offline HPLC run was complete. Traditional analytical workflows treat the reaction vessel as a black box, extracting data at discrete checkpoints and constructing a retrospective narrative from isolated snapshots. This is, at a fundamental level, an epistemological limitation. The chemical event and its analysis are separated in both time and space.
The consequences compound at scale. In pharmaceutical API development, this temporal gap is estimated to account for a significant fraction of the reproducibility failures that plague early-stage manufacturing campaigns. In specialty chemical and agrochemical production, it manifests as batch-to-batch inconsistency — the kind that erodes customer confidence and inflates rework costs. The missing layer is not more data at the end of the process. It is continuous molecular intelligence throughout it.
Process Analytical Technology (PAT), formally defined by the FDA in its landmark 2004 guidance, was the first regulatory acknowledgment that this gap needed closing. The philosophy — analyze, understand, and control — was sound. But for two decades, implementation remained constrained by the interpretive burden: spectral data streams are noisy, high-dimensional, and non-trivially mapped onto chemical meaning without substantial domain expertise and painstaking model development. What has changed now is the interpreter. And the interpreter is artificial intelligence.
Molecular Fingerprinting at Machine Speed: The Spectroscopy–AI Convergence
Vibrational spectroscopy — encompassing Raman, mid-infrared (MIR), near-infrared (NIR), and their surface-enhanced variants — has always possessed something remarkable: every molecular species vibrates at characteristic frequencies, encoding its identity in a spectral signature as unique as a fingerprint. The challenge was never detection. It was interpretation, and specifically, interpretation at the speed and scale demanded by industrial R&D.
The past two years have produced a step-change in this interpretive capacity. Transformer-based architectures, trained on datasets spanning millions of spectra, have demonstrated the ability to perform structure elucidation from raw IR data with top-1 prediction accuracies approaching 64%, and top-10 accuracies exceeding 83%. Platforms such as Vib2Mol have further extended this capability into generative territory, enabling the reconstruction of molecular structures and even the prediction of reaction products directly from vibrational spectral data — a capability with enormous implications for closed-loop experimental systems.
What makes this genuinely transformative for the working chemist is not the benchmark accuracy alone. It is the latency. These models return chemically actionable structural understanding in near-real time. A reaction mixture that would previously have required hours of expert spectral interpretation can now yield its primary chemical narrative in milliseconds. The bottleneck between observation and decision has been, for the first time, effectively removed.
Beyond Single-Modal Analysis: The Rise of Multimodal Spectral Fusion
Any single spectroscopic modality carries an inherent information ceiling. Raman is exceptionally sensitive to non-polar, symmetric molecular vibrations; mid-IR excels at polar functional groups. Neither alone provides a complete chemical picture of a complex formulation containing APIs, excipients, solvents, and transient intermediates simultaneously. The field has long understood this theoretically. What it lacked was the computational architecture to exploit it practically.
Multimodal fusion networks — models that ingest and jointly process data streams from Raman, FTIR, mass spectrometry, NMR, and UV-Vis simultaneously — are now closing this gap decisively. The analogy most apt here is not from chemistry but from diagnostic medicine: just as a radiologist who can simultaneously read an MRI, CT, and PET scan produces a more confident and complete diagnosis than one who reads each modality sequentially, a multimodal spectral AI provides a richer, more confident chemical fingerprint than any single probe technique could achieve in isolation. Trace impurities invisible to one technique surface in another. Polymorphic transitions that confound Raman become unambiguous in the NMR signal. The integrated picture is fundamentally superior.
Dual NIR-Raman configurations deployed in fermentation monitoring have demonstrated this concretely: by fusing both modalities with real-time AI feedback, researchers documented measurably shorter process cycles, reduced waste generation, and demonstrably more accurate scale-up of industrial throughput. This is not a theoretical benefit on a laboratory whiteboard — it is a documented commercial advantage, achievable today, with instrumentation that is increasingly miniaturized, portable, and inline-deployable.
| Modality | Primary Sensitivity | AI Enhancement | Deployment Mode | Key Application |
|---|---|---|---|---|
| Raman | Non-polar bonds, C-C stretches, ring structures | CNN-based peak deconvolution; polymorphic ID | In-situ probe / flow cell | Crystallization endpoint, solid-state form control |
| FTIR / ATR | Polar functional groups (C=O, N-H, O-H) | Transformer structure elucidation; real-time conversion tracking | ATR flow-through probe | Reaction completion, intermediate detection |
| NIR | Overtone bands; moisture, API concentration | PLS + deep learning hybrid; multicomponent quantification | Inline / at-line | Blend uniformity, concentration profiling |
| NMR (benchtop) | Structural assignment; stereochemistry | Automated shimming; AI peak assignment; kinetic monitoring | Flow NMR; at-line benchtop | Impurity profiling, chiral purity confirmation |
| MS (online) | Isotopic patterns; trace impurities | ML-based automated spectral deconvolution; impurity classification | Headspace / flow injection | Mass balance, byproduct identification |
| Multimodal Fusion | Complete chemical fingerprint | Foundation models (SpectraFM, Vib2Mol); cross-domain learning | Integrated inline system | Autonomous closed-loop process control |
Physics-Informed Neural Networks: When Chemistry Teaches the Algorithm
A persistent criticism of deep learning models in chemistry has been their tendency to operate as statistical pattern-matchers divorced from physical reality — capable of impressive accuracy within their training distribution while failing catastrophically when encountering molecular environments that were underrepresented in their training data. This critique, while increasingly less applicable as training corpora grow, retains genuine force in precision chemistry applications where the penalty for a wrong prediction is not a poor benchmark score but a failed batch, a missed regulatory submission, or a safety incident.
Physics-Informed Neural Networks (PINNs) represent the most principled answer to this concern. Rather than learning exclusively from data, PINNs embed hard constraints derived from known chemical physics — vibrational symmetry rules, IR-Raman selection principles, anharmonicity corrections, conservation laws — directly into the training objective. The network is not permitted to make predictions that violate thermodynamic reality. It is, in effect, taught chemistry before it is taught statistics.
The practical consequences are profound. PINN-based spectral models exhibit substantially reduced overfitting, improved generalization across instrument configurations and sample matrices, and — critically — outputs that can be verified for physical consistency by domain experts. In regulated pharmaceutical environments where analytical models must be validated, justified, and periodically recalibrated, this interpretability is not an academic luxury. It is a regulatory prerequisite. The explainability tools emerging alongside these architectures, such as SpecReX, provide quantified uncertainty estimates alongside predictions — giving the scientist not just an answer but a confidence envelope within which to make decisions.
"The spectroscopic model that cannot explain why it reached its conclusion is, in a regulated chemistry laboratory, simply not deployable. Physics-informed AI eliminates that barrier — not by simplifying the chemistry, but by ensuring the algorithm has learned it."
From PAT Tool to Autonomous Intelligence: The Self-Driving Laboratory Trajectory
The vision of the self-driving laboratory — a closed-loop experimental system that designs, executes, and interprets experiments without continuous human intervention — has moved from speculative futures paper to documented reality over the past eighteen months. The architecture enabling this shift is precisely the convergence described above: AI-powered spectroscopic interpretation feeding continuously into a reinforcement learning agent that adjusts process parameters, designs the next experimental perturbation, and iterates toward a target outcome.
In a prototypical implementation, a Raman probe embedded in a flow reactor transmits a spectral scan every thirty seconds. The AI system identifies reagent conversion percentages, detects the onset of a known impurity signature at below-threshold concentration, and — without human intervention — adjusts the reactor temperature by two degrees and the feed ratio by a calculated increment. The entire decision cycle, from spectral acquisition to actuator command, executes in under a minute. A synthesis that previously required a skilled operator present throughout a twelve-hour run becomes, in this paradigm, a supervised automated process requiring only endpoint verification.
This is not science fiction occurring at a handful of elite academic institutions. Dual NIR-Raman feedback systems deployed in industrial fermentation environments have already demonstrated measurable reductions in process cycle times and waste generation. The pharmaceutical industry, driven by Quality-by-Design (QbD) mandates and the FDA's PAT guidance, is increasingly embedding these systems into API synthesis campaigns. The transition is underway globally — in BASF's process chemistry units, in AstraZeneca's continuous manufacturing platforms, and in the mid-scale specialty chemical producers who cannot afford the batch failure rates that characterized pre-digital process development.
The Persistent Bottleneck: Raw Spectral Intelligence Without Formulation Context
Despite this remarkable progress, a critical gap persists — and it is one that the spectroscopy and instrumentation community has been largely silent about, because it lies outside their domain. Spectral AI, however sophisticated, generates chemical intelligence about the contents of a vessel at a specific moment in time. What it does not inherently do is connect that intelligence to everything else that defines a formulation's commercial and regulatory existence: its raw material sourcing history, its regulatory status across jurisdictions, its performance specification envelope, its version lineage across R&D iterations, and the sustainability profile of each constituent ingredient.
Consider a concrete scenario: an in-situ NIR model detects, during a specialty coating synthesis, that the concentration of a particular solvent impurity is approaching the threshold above which it would affect film adhesion. The spectral AI raises a flag. But what action should the formulator take? The answer depends on factors the spectral model has no access to: whether the impurity exceeds any regulatory limit under REACH; whether a formulation version from eight weeks ago — which passed the adhesion test despite a similar signal — used a different raw material batch; whether substituting the solvent mid-batch would violate the current version's specification record. These questions require a formulation intelligence platform, not a spectrometer.
The Missing Layer: Spectroscopic AI answers the question "What is in this vessel right now?" Formulation intelligence answers the question "What should I do about it, given everything I know about this product, its history, and its regulatory obligations?" The two are complementary, not competitive — but only when they are connected within a unified platform.
Where ChemCopilot Operates: Connecting Spectral Events to Formulation Decisions
ChemCopilot is built precisely at this intersection. As an AI-native Product Lifecycle Management platform for the chemical industry, ChemCopilot's architecture is designed to receive, contextualize, and act upon exactly the kind of time-stamped molecular events that in-situ spectroscopy generates. When a spectral AI system detects a deviation — a polymorphic shift, an unexpected intermediate, an impurity onset — ChemCopilot provides the downstream decision intelligence that transforms that observation into a governed, documented, and regulatory-aware response.
Concretely, ChemCopilot's formulation versioning system links spectral event data to the precise batch parameters, raw material lots, and formulation versions in effect at the moment of detection. Its AI agents can cross-reference the observed signal against the historical performance of analogous batches — identifying whether the current deviation pattern has been encountered before, what corrective action proved effective, and whether any regulatory submission is affected. Its compliance layer ensures that any reformulation decision triggered by a spectral event is automatically evaluated against the product's current regulatory requirements across all relevant jurisdictions.
This is the distinction between spectral data and formulation intelligence. A Raman probe tells you that a compound is crystallizing in the wrong polymorph. ChemCopilot tells you which batches from the past eighteen months had the same signature, which raw material lot was implicated in the majority of those cases, whether the current specification can accommodate a minor process adjustment without triggering a regulatory variation filing, and what the CO₂ footprint differential is between the corrective action options available to you. The spectroscopic system generates the signal. ChemCopilot generates the decision.
Spectral Foundation Models and the Impending Paradigm Shift in Chemical Data Infrastructure
The research community is now converging on what may represent the most consequential development in analytical chemistry AI since the advent of chemometrics: spectroscopy foundation models. Platforms such as SpectrumLab, built upon over 1.2 million distinct chemical substance spectra, and the Vib2Mol framework's generative encoder-decoder architecture, are establishing the scaffolding for models that will, in the near future, handle peak prediction, spectral reconstruction, structure elucidation, and reaction product prediction as unified tasks within a single multi-modal large language model framework.
The implications for chemical R&D are non-trivial. Today, deploying a spectroscopic PAT method in a new production environment requires building and validating a new chemometric model — a process that can take months and demands specialist expertise. Foundation models trained across instruments, matrices, and chemical classes will compress this deployment cycle dramatically, enabling even resource-constrained R&D organizations to implement sophisticated inline analytics without dedicated spectroscopy modeling teams. The democratization of analytical intelligence is not a distant aspiration; it is arriving with the current generation of multimodal LLMs being benchmarked against spectroscopic tasks.
The challenge that will persist — and that no spectroscopy foundation model alone can resolve — is the one of proprietary chemical knowledge. A foundation model trained on public spectral databases has no knowledge of your specific formulation's historical performance, your supplier's typical impurity profile, or the batch-specific parameters that distinguish a passing product from a failing one in your particular application. This gap is precisely where ChemCopilot's architecture of privately-trained, client-isolated AI models becomes decisive. The foundation model provides the spectral intelligence. ChemCopilot provides the institutional memory.
Implementation Landscape: What Organizations Need to Build This Capability
The pathway from current practice to AI-powered spectral formulation intelligence is not a single capital investment decision. It is an architectural evolution that proceeds in stages, each delivering standalone value while building toward the integrated capability that defines the state of the art.
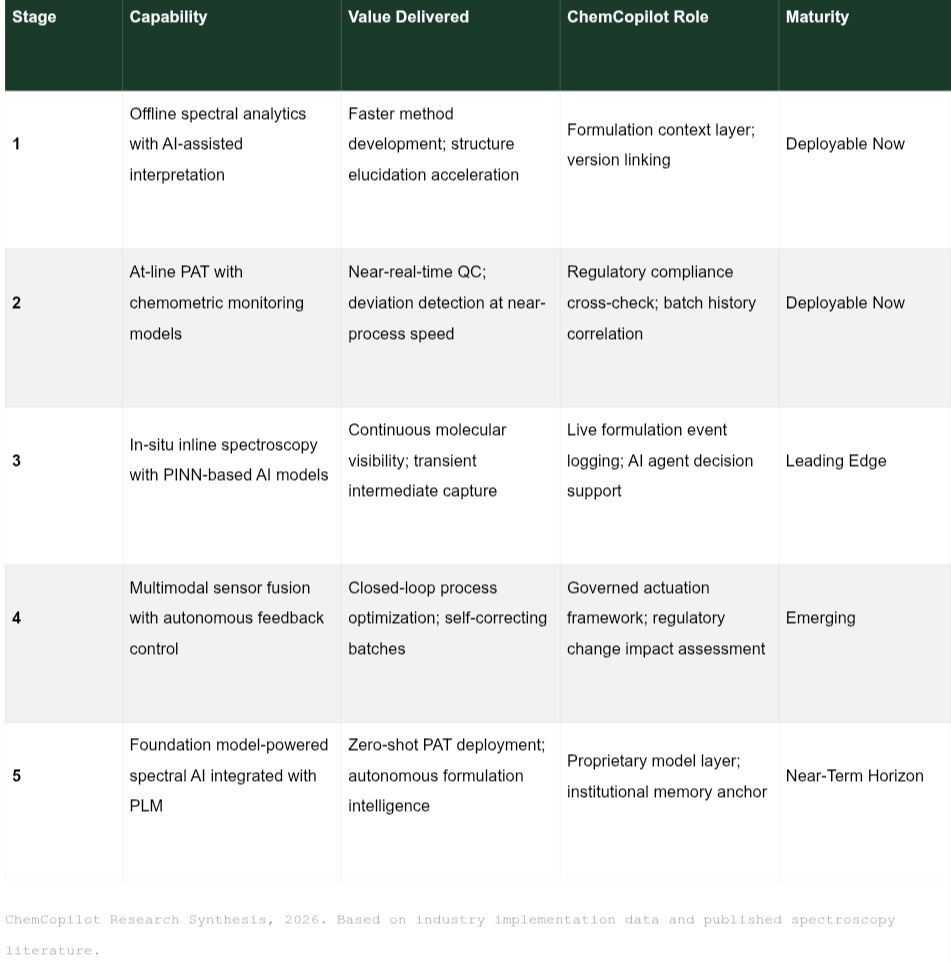
Organizations at Stage 1 or 2 — the majority of mid-tier chemical and pharmaceutical producers — are not behind. They are at the threshold of a compounding capability build. The foundational investment in data infrastructure and formulation governance made today determines the speed at which Stages 3, 4, and 5 become accessible. The organizations that will benefit most from foundation model spectroscopy in 2027 and 2028 are those that began structuring their formulation data coherently in 2025 and 2026.
Conclusion: The Molecule Has Been Speaking All Along
Chemistry has always generated an extraordinary density of information. Every bond vibration, every photon absorbed, every mass fragment in an ionization chamber carries molecular meaning. The discipline's historical inability to interpret this information in real time was not a failure of chemistry — it was a limitation of the tools available to process it. Those limitations are now being systematically dismantled by the convergence of multimodal spectroscopy, physics-informed machine learning, and high-capacity foundation models.
What is emerging from this convergence is something genuinely novel: a chemistry that is, for the first time, continuously self-aware during the act of being performed. Reactions that proceeded in informational darkness for most of their history are now bathed in an unbroken stream of molecular intelligence. The question no longer is whether this intelligence can be generated. It is whether the organizations receiving it have the infrastructure to act on it wisely — with full awareness of formulation history, regulatory context, and commercial consequence.
That infrastructure is precisely what ChemCopilot provides. Not as a spectroscopy platform — there are excellent, specialized providers for that — but as the formulation intelligence layer that turns a molecular observation into a governed, context-rich, decision-ready event. The molecule has been speaking all along. ChemCopilot ensures that what it says is heard, understood, and acted upon.
Your Formulation Data Deserves a Smarter Framework
ChemCopilot connects your spectral observations, batch records, regulatory requirements, and formulation history into a single, AI-native decision environment — built for the pace of modern chemical R&D.